Week-4 Poefier
We continue to move forward in the project. Now we have come to the stage where we should determine our method. This week we tested our data with specific machine learning algorithms and compared the accuracy results. After reading our data, we used Tfidf Vectorizer to extract features from the dataset. Since we don’t have a separate data for testing, we randomly splitted our data so that %80 of it is used for training the model and rest for testing and accuracy. We have tested every algorithm 50 times and got the average accuracies.
You can see the code samples and test results below. We will share these results with the teaching assistant, and we will decide our method precisely.
First, we applied K-nearest neighbor method. After trying different k values, when k=3 the accuracy was highest so we chose to use this value for both KNN and W-KNN.
neighbors = np.arange(1, 9)
train_accuracy = np.empty(len(neighbors))
test_accuracy = np.empty(len(neighbors))
for i, k in enumerate(neighbors):
# Setup a knn classifier with k neighbors
knn = KNeighborsClassifier(n_neighbors=k)
# Fit the model
knn.fit(X_train, y_train)
# Compute accuracy on the training set
train_accuracy[i] = knn.score(X_train, y_train)
# Compute accuracy on the test set
test_accuracy[i] = knn.score(X_test, y_test)
plt.title('k-NN Varying number of neighbors')
plt.plot(neighbors, test_accuracy, label='Testing Accuracy')
plt.plot(neighbors, train_accuracy, label='Training accuracy')
plt.legend()
plt.xlabel('Number of neighbors')
plt.ylabel('Accuracy')
plt.show()
After that we created models with different classifiers and trained them.
K-Nearest Neighbors:
knn = KNeighborsClassifier(n_neighbors=3 ,metric='euclidean')knn.fit(X_train,y_train)knn.score(X_test,y_test)
Weighted K-Nearest Neighbors:
wknn = KNeighborsClassifier(n_neighbors=3, metric='euclidean', weights='distance')wknn.fit(X_train, y_train)wknn.score(X_test, y_test))
Logistic Regression:
logistic = LogisticRegression(solver='liblinear', random_state=15).fit(X_train, y_train)logistic.score(X_test,y_test)
Support Vector Classifier:
svclassifier = SVC(kernel='linear')svclassifier.fit(X_train, y_train)svclassifier.score(X_test,y_test)
Naïve Bayes:
nb = MultinomialNB().fit(X_train, y_train)predicted = nb.predict(X_test)np.mean(predicted == y_test)
Decision Tree Classifier:
dtclassifier = DecisionTreeClassifier()dtclassifier.fit(X_train, y_train)dtclassifier.score(X_test,y_test)
Random Forest Classifier:
randomf_clf = RandomForestClassifier(n_estimators=100)randomf_clf.fit(X_train, y_train)randomf_clf.score(X_test,y_test)
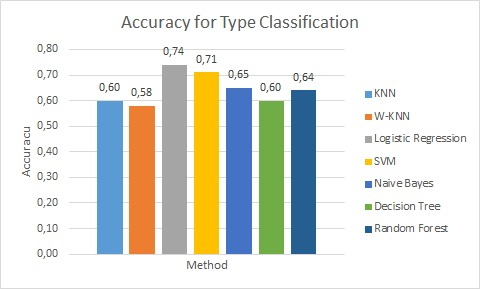
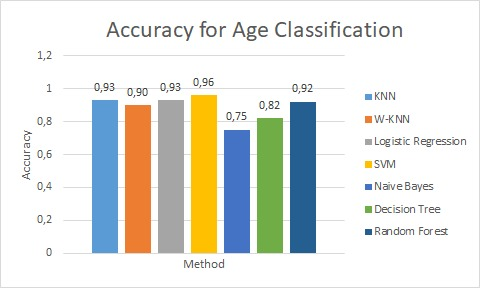
In below you can see a table of accuracy. We run tests for both type and age classification and it’s clear that SVM has best accuracy for age classification. For type classification Logistic Regression method has the highest accuracy.

For better understanding we visualize our test results. In below you can see them clearly.
Dataset
You can reach our dataset from here.
Group Members
Alihan Karatatar — 21904324
Atakan Yüksel — 21627892
Ceren Korkmaz — 21995445